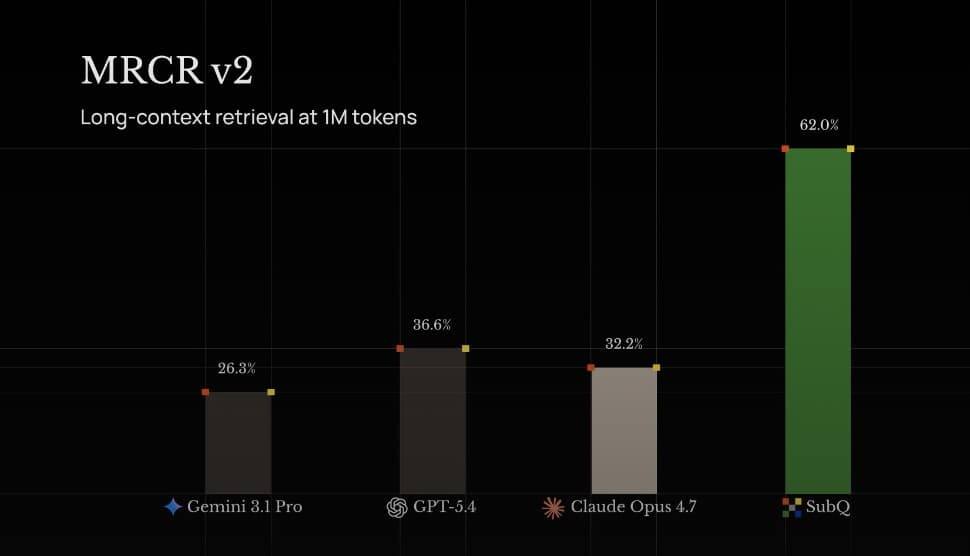
A Miami startup says it has found a way around one of the biggest bottlenecks in large language models: the quadratic cost of transformer attention. Its model, SubQ, is being pitched as a faster, cheaper system for very long contexts, with claims that it can chew through hundreds of documents or huge codebases in a […]