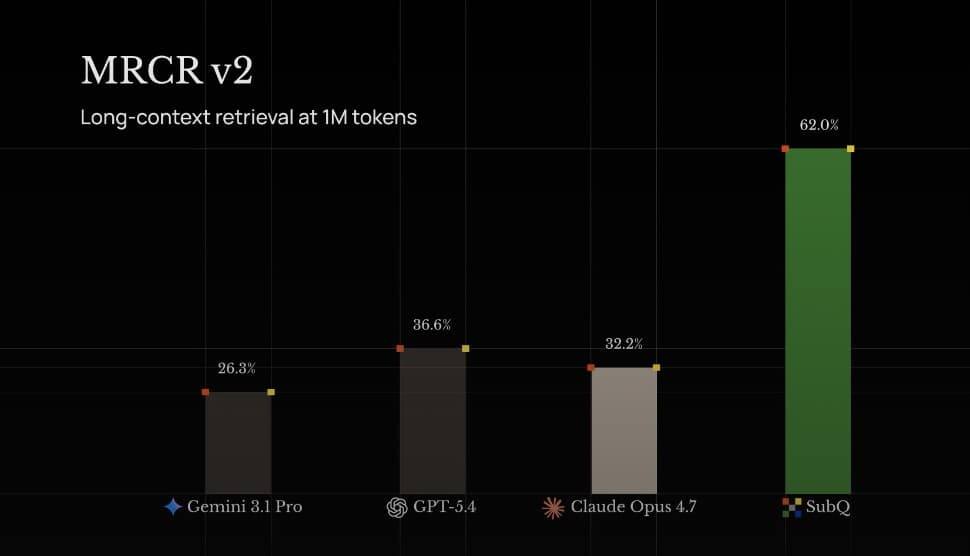
A Miami startup says it has found a way around one of the biggest bottlenecks in large language models: the quadratic cost of transformer attention. Its model, SubQ, is being pitched as a faster, cheaper system for very long contexts, with claims that it can chew through hundreds of documents or huge codebases in a single pass.
Subquadratic says SubQ can handle up to 12 million tokens of context, far above the roughly 1 million token ceiling the company says most current models sit near. That is a bold claim in a field where ”we beat transformers” is often followed by a quieter correction a few weeks later.
What SubQ is claiming
The pitch is straightforward: if the model can truly process that much text efficiently, it becomes much more useful for document search, retrieval, and code analysis at scale.
- Claimed context window: up to 12 million tokens
- Typical modern model limit cited by the company: about 1 million tokens
- Promised gains: lower compute, lower energy use, faster long-context processing
Sparse attention, not dense attention
The technical bet is a shift away from dense attention, where every token interacts with every other token and computational cost rises sharply as sequences get longer. Subquadratic says SubQ uses sparse attention instead, selecting only part of those interactions to cut the load.
That idea is not crazy on its face. Plenty of AI teams have tried to tame the attention bottleneck, and the broader industry has spent years optimizing long-context inference because the economics get ugly fast. OpenAI, Anthropic, Google, and others have all chased longer windows, but extending context without turning GPUs into space heaters is still the hard part.
Appen’s results add some weight
Subquadratic later pointed to additional testing from Appen, which it says found strong speed and efficiency results, along with competitive performance on programming tasks. The company also says SubQ showed a multiple-fold speedup versus FlashAttention-based approaches and performed well on LiveCodeBench, a benchmark for coding ability.
The catch, as critics keep pointing out, is that benchmarks are not the same thing as real-world reliability. A model can look excellent in a controlled test and still stumble when asked to operate across messy, diverse workloads.
There is also an important asterisk in the architecture story: Subquadratic says SubQ builds partly on existing open Qwen models, adapting them to its own method rather than replacing everything from scratch. That does not make the work trivial, but it does complicate the company’s implied message that it has simply broken free of the transformer era altogether.
The real test is still missing
For now, access is limited to a small group of users, including corporate customers, which means the wider AI community cannot yet kick the tires properly. Until that changes, Subquadratic’s story sits in a familiar place: interesting enough to watch, not proven enough to crown.
The next question is whether broader testing confirms that SubQ is a genuine architectural shortcut or just a very well-tuned version of an existing playbook. If independent evaluators get the same results, the company will have earned serious attention. If not, the hype cycle will do what it always does.