• 17 min read
ChatGPT for Clinicians goes free for verified U.S. medical staff
OpenAI is rolling out a clinician-focused version of ChatGPT that targets a painfully familiar problem in healthcare: too much paperwork, too little time. The new ChatGPT for Clinicians is free for verified physicians, N

Image: openai.com
There is a practical edge here that many health-tech vendors have missed: clinicians do not need another generic chatbot with a stethoscope emoji. They need fewer clicks, better citations, and less time spent stitching together a note from five tabs and a prayer. OpenAI is clearly trying to sell reliability, not novelty.
HealthBench Professional is the new scoreboard
The other big piece is evaluation. OpenAI is introducing HealthBench Professional, an open benchmark built from physician-authored conversations covering care consults, writing and documentation, and medical research. The company says it used multi-stage physician adjudication, careful filtering, and a deliberate dose of red teaming to make the set hard enough to matter. That is sensible, because medical AI tends to look impressive right up until someone asks a sharper question than the demo script anticipated.
OpenAI says physician advisors reviewed more than 700,000 model responses overall, and before release they tested 6,924 conversations from daily clinical work. The company says physicians rated 99.6% of responses as safe and accurate, and on a subset with ground-truth citations, ChatGPT for Clinicians cited sources more often than human physicians. Those numbers are impressive, but they also underline the bar: healthcare buyers will want transparency, not just a victory lap.
Access starts in the U.S., then expands
The free version is available now to verified U.S. clinicians in the listed professions, with broader access planned over time. OpenAI says it will begin piloting access outside the U.S. with the Better Evidence Network, subject to local regulations. It is also releasing a Health Blueprint with recommendations for responsible AI use in U.S. healthcare, which reads as much like a policy signal as a product note.
Recommended reading
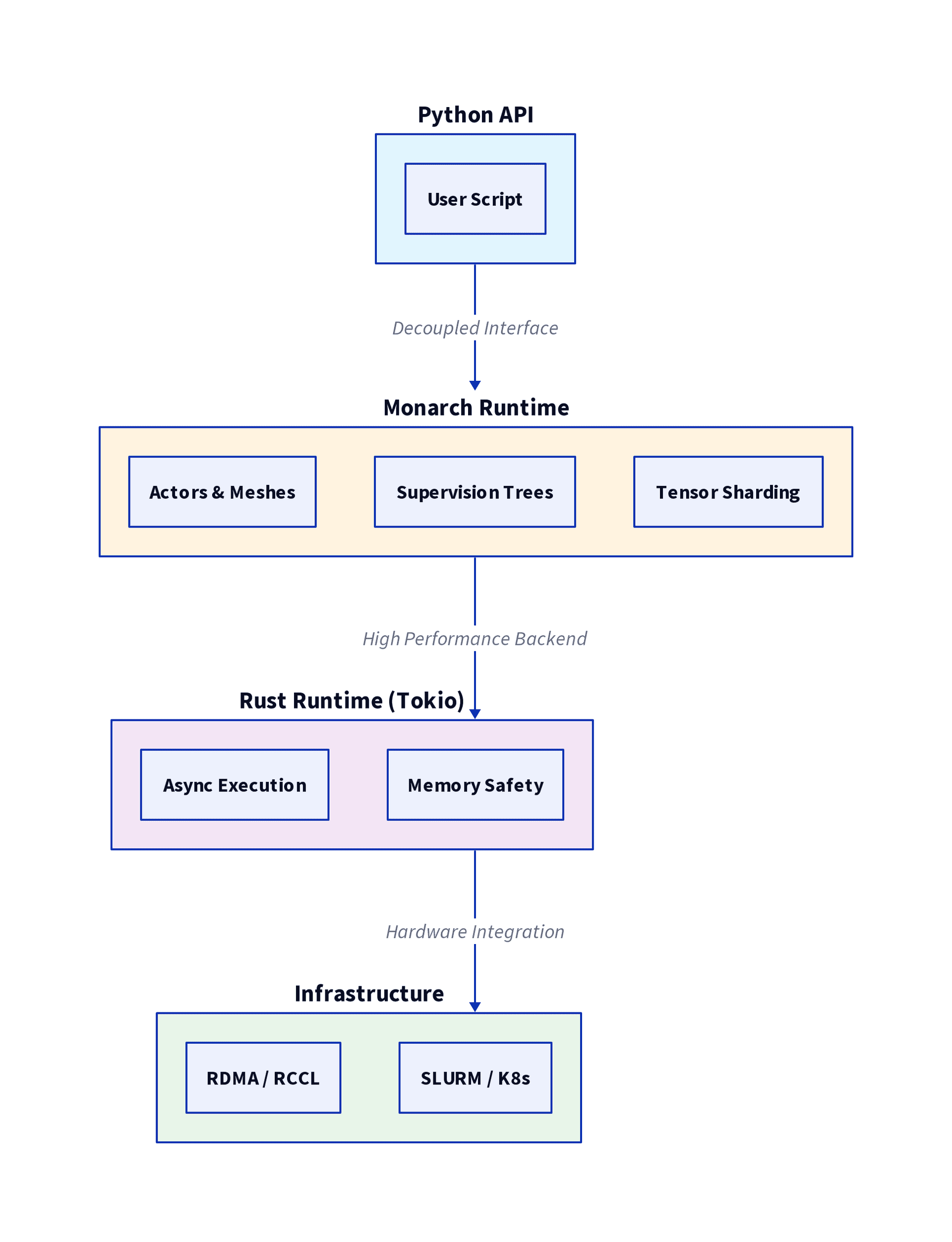
PyTorch Monarch brings fault-tolerant training to AMD GPUs
The bigger trend is obvious enough: AI in medicine is moving from experimental sidekick to infrastructure. Competitors are racing toward the same goal from different angles, but OpenAI is leaning hard on scale, citations, and workflow fit. If it can keep the clinical guardrails tight, this could become one of the first AI products healthcare teams actually use every day instead of only discussing at conferences.
There is a practical edge here that many health-tech vendors have missed: clinicians do not need another generic chatbot with a stethoscope emoji. They need fewer clicks, better citations, and less time spent stitching together a note from five tabs and a prayer. OpenAI is clearly trying to sell reliability, not novelty.
HealthBench Professional is the new scoreboard
The other big piece is evaluation. OpenAI is introducing HealthBench Professional, an open benchmark built from physician-authored conversations covering care consults, writing and documentation, and medical research. The company says it used multi-stage physician adjudication, careful filtering, and a deliberate dose of red teaming to make the set hard enough to matter. That is sensible, because medical AI tends to look impressive right up until someone asks a sharper question than the demo script anticipated.
OpenAI says physician advisors reviewed more than 700,000 model responses overall, and before release they tested 6,924 conversations from daily clinical work. The company says physicians rated 99.6% of responses as safe and accurate, and on a subset with ground-truth citations, ChatGPT for Clinicians cited sources more often than human physicians. Those numbers are impressive, but they also underline the bar: healthcare buyers will want transparency, not just a victory lap.
Access starts in the U.S., then expands
The free version is available now to verified U.S. clinicians in the listed professions, with broader access planned over time. OpenAI says it will begin piloting access outside the U.S. with the Better Evidence Network, subject to local regulations. It is also releasing a Health Blueprint with recommendations for responsible AI use in U.S. healthcare, which reads as much like a policy signal as a product note.
The bigger trend is obvious enough: AI in medicine is moving from experimental sidekick to infrastructure. Competitors are racing toward the same goal from different angles, but OpenAI is leaning hard on scale, citations, and workflow fit. If it can keep the clinical guardrails tight, this could become one of the first AI products healthcare teams actually use every day instead of only discussing at conferences.
There is a practical edge here that many health-tech vendors have missed: clinicians do not need another generic chatbot with a stethoscope emoji. They need fewer clicks, better citations, and less time spent stitching together a note from five tabs and a prayer. OpenAI is clearly trying to sell reliability, not novelty.
HealthBench Professional is the new scoreboard
The other big piece is evaluation. OpenAI is introducing HealthBench Professional, an open benchmark built from physician-authored conversations covering care consults, writing and documentation, and medical research. The company says it used multi-stage physician adjudication, careful filtering, and a deliberate dose of red teaming to make the set hard enough to matter. That is sensible, because medical AI tends to look impressive right up until someone asks a sharper question than the demo script anticipated.
OpenAI says physician advisors reviewed more than 700,000 model responses overall, and before release they tested 6,924 conversations from daily clinical work. The company says physicians rated 99.6% of responses as safe and accurate, and on a subset with ground-truth citations, ChatGPT for Clinicians cited sources more often than human physicians. Those numbers are impressive, but they also underline the bar: healthcare buyers will want transparency, not just a victory lap.
Access starts in the U.S., then expands
The free version is available now to verified U.S. clinicians in the listed professions, with broader access planned over time. OpenAI says it will begin piloting access outside the U.S. with the Better Evidence Network, subject to local regulations. It is also releasing a Health Blueprint with recommendations for responsible AI use in U.S. healthcare, which reads as much like a policy signal as a product note.
The bigger trend is obvious enough: AI in medicine is moving from experimental sidekick to infrastructure. Competitors are racing toward the same goal from different angles, but OpenAI is leaning hard on scale, citations, and workflow fit. If it can keep the clinical guardrails tight, this could become one of the first AI products healthcare teams actually use every day instead of only discussing at conferences.
There is a practical edge here that many health-tech vendors have missed: clinicians do not need another generic chatbot with a stethoscope emoji. They need fewer clicks, better citations, and less time spent stitching together a note from five tabs and a prayer. OpenAI is clearly trying to sell reliability, not novelty.
HealthBench Professional is the new scoreboard
The other big piece is evaluation. OpenAI is introducing HealthBench Professional, an open benchmark built from physician-authored conversations covering care consults, writing and documentation, and medical research. The company says it used multi-stage physician adjudication, careful filtering, and a deliberate dose of red teaming to make the set hard enough to matter. That is sensible, because medical AI tends to look impressive right up until someone asks a sharper question than the demo script anticipated.
OpenAI says physician advisors reviewed more than 700,000 model responses overall, and before release they tested 6,924 conversations from daily clinical work. The company says physicians rated 99.6% of responses as safe and accurate, and on a subset with ground-truth citations, ChatGPT for Clinicians cited sources more often than human physicians. Those numbers are impressive, but they also underline the bar: healthcare buyers will want transparency, not just a victory lap.
Access starts in the U.S., then expands
The free version is available now to verified U.S. clinicians in the listed professions, with broader access planned over time. OpenAI says it will begin piloting access outside the U.S. with the Better Evidence Network, subject to local regulations. It is also releasing a Health Blueprint with recommendations for responsible AI use in U.S. healthcare, which reads as much like a policy signal as a product note.
The bigger trend is obvious enough: AI in medicine is moving from experimental sidekick to infrastructure. Competitors are racing toward the same goal from different angles, but OpenAI is leaning hard on scale, citations, and workflow fit. If it can keep the clinical guardrails tight, this could become one of the first AI products healthcare teams actually use every day instead of only discussing at conferences.
There is a practical edge here that many health-tech vendors have missed: clinicians do not need another generic chatbot with a stethoscope emoji. They need fewer clicks, better citations, and less time spent stitching together a note from five tabs and a prayer. OpenAI is clearly trying to sell reliability, not novelty.
HealthBench Professional is the new scoreboard
The other big piece is evaluation. OpenAI is introducing HealthBench Professional, an open benchmark built from physician-authored conversations covering care consults, writing and documentation, and medical research. The company says it used multi-stage physician adjudication, careful filtering, and a deliberate dose of red teaming to make the set hard enough to matter. That is sensible, because medical AI tends to look impressive right up until someone asks a sharper question than the demo script anticipated.
OpenAI says physician advisors reviewed more than 700,000 model responses overall, and before release they tested 6,924 conversations from daily clinical work. The company says physicians rated 99.6% of responses as safe and accurate, and on a subset with ground-truth citations, ChatGPT for Clinicians cited sources more often than human physicians. Those numbers are impressive, but they also underline the bar: healthcare buyers will want transparency, not just a victory lap.
Access starts in the U.S., then expands
The free version is available now to verified U.S. clinicians in the listed professions, with broader access planned over time. OpenAI says it will begin piloting access outside the U.S. with the Better Evidence Network, subject to local regulations. It is also releasing a Health Blueprint with recommendations for responsible AI use in U.S. healthcare, which reads as much like a policy signal as a product note.
The bigger trend is obvious enough: AI in medicine is moving from experimental sidekick to infrastructure. Competitors are racing toward the same goal from different angles, but OpenAI is leaning hard on scale, citations, and workflow fit. If it can keep the clinical guardrails tight, this could become one of the first AI products healthcare teams actually use every day instead of only discussing at conferences.
There is a practical edge here that many health-tech vendors have missed: clinicians do not need another generic chatbot with a stethoscope emoji. They need fewer clicks, better citations, and less time spent stitching together a note from five tabs and a prayer. OpenAI is clearly trying to sell reliability, not novelty.
HealthBench Professional is the new scoreboard
The other big piece is evaluation. OpenAI is introducing HealthBench Professional, an open benchmark built from physician-authored conversations covering care consults, writing and documentation, and medical research. The company says it used multi-stage physician adjudication, careful filtering, and a deliberate dose of red teaming to make the set hard enough to matter. That is sensible, because medical AI tends to look impressive right up until someone asks a sharper question than the demo script anticipated.
OpenAI says physician advisors reviewed more than 700,000 model responses overall, and before release they tested 6,924 conversations from daily clinical work. The company says physicians rated 99.6% of responses as safe and accurate, and on a subset with ground-truth citations, ChatGPT for Clinicians cited sources more often than human physicians. Those numbers are impressive, but they also underline the bar: healthcare buyers will want transparency, not just a victory lap.
Access starts in the U.S., then expands
The free version is available now to verified U.S. clinicians in the listed professions, with broader access planned over time. OpenAI says it will begin piloting access outside the U.S. with the Better Evidence Network, subject to local regulations. It is also releasing a Health Blueprint with recommendations for responsible AI use in U.S. healthcare, which reads as much like a policy signal as a product note.
The bigger trend is obvious enough: AI in medicine is moving from experimental sidekick to infrastructure. Competitors are racing toward the same goal from different angles, but OpenAI is leaning hard on scale, citations, and workflow fit. If it can keep the clinical guardrails tight, this could become one of the first AI products healthcare teams actually use every day instead of only discussing at conferences.
- Free access for verified U.S. physicians, NPs, PAs, and pharmacists
- Trusted clinical search with real-time cited answers
- Deep research across medical journals with editable source preferences
- CME credit support for eligible evidence reviews
- Optional HIPAA support through a BAA for eligible accounts
There is a practical edge here that many health-tech vendors have missed: clinicians do not need another generic chatbot with a stethoscope emoji. They need fewer clicks, better citations, and less time spent stitching together a note from five tabs and a prayer. OpenAI is clearly trying to sell reliability, not novelty.
HealthBench Professional is the new scoreboard
The other big piece is evaluation. OpenAI is introducing HealthBench Professional, an open benchmark built from physician-authored conversations covering care consults, writing and documentation, and medical research. The company says it used multi-stage physician adjudication, careful filtering, and a deliberate dose of red teaming to make the set hard enough to matter. That is sensible, because medical AI tends to look impressive right up until someone asks a sharper question than the demo script anticipated.
OpenAI says physician advisors reviewed more than 700,000 model responses overall, and before release they tested 6,924 conversations from daily clinical work. The company says physicians rated 99.6% of responses as safe and accurate, and on a subset with ground-truth citations, ChatGPT for Clinicians cited sources more often than human physicians. Those numbers are impressive, but they also underline the bar: healthcare buyers will want transparency, not just a victory lap.
Access starts in the U.S., then expands
The free version is available now to verified U.S. clinicians in the listed professions, with broader access planned over time. OpenAI says it will begin piloting access outside the U.S. with the Better Evidence Network, subject to local regulations. It is also releasing a Health Blueprint with recommendations for responsible AI use in U.S. healthcare, which reads as much like a policy signal as a product note.
The bigger trend is obvious enough: AI in medicine is moving from experimental sidekick to infrastructure. Competitors are racing toward the same goal from different angles, but OpenAI is leaning hard on scale, citations, and workflow fit. If it can keep the clinical guardrails tight, this could become one of the first AI products healthcare teams actually use every day instead of only discussing at conferences.
OpenAI is rolling out a clinician-focused version of ChatGPT that targets a painfully familiar problem in healthcare: too much paperwork, too little time. The new ChatGPT for Clinicians is free for verified physicians, NPs, PAs, and pharmacists in the U.S., and it is pitched as a tool for documentation, medical research, care consults, and the kind of administrative chores that eat into patient time.
That timing is not accidental. OpenAI says physician use of AI is at an all-time high, with 72% reporting use in clinical practice in a 2026 AMA survey, up from 48% last year. In other words, the fight is no longer over whether clinicians use AI at all; it is over which tool is trusted enough to sit between a doctor and a mountain of notes, guidelines, and billing codes.
What ChatGPT for Clinicians includes
The product bundles several features aimed squarely at workflow speed rather than flashy consumer chat tricks. OpenAI is offering access to its current frontier models for healthcare use cases, reusable skills for repeat tasks such as referral letters and prior authorization, and a “trusted clinical search” mode that returns cited answers from peer-reviewed medical sources. It also adds deep research for literature reviews, optional HIPAA support through a Business Associate Agreement for eligible accounts, and privacy protections including multi-factor authentication.
- Free access for verified U.S. physicians, NPs, PAs, and pharmacists
- Trusted clinical search with real-time cited answers
- Deep research across medical journals with editable source preferences
- CME credit support for eligible evidence reviews
- Optional HIPAA support through a BAA for eligible accounts
There is a practical edge here that many health-tech vendors have missed: clinicians do not need another generic chatbot with a stethoscope emoji. They need fewer clicks, better citations, and less time spent stitching together a note from five tabs and a prayer. OpenAI is clearly trying to sell reliability, not novelty.
HealthBench Professional is the new scoreboard
The other big piece is evaluation. OpenAI is introducing HealthBench Professional, an open benchmark built from physician-authored conversations covering care consults, writing and documentation, and medical research. The company says it used multi-stage physician adjudication, careful filtering, and a deliberate dose of red teaming to make the set hard enough to matter. That is sensible, because medical AI tends to look impressive right up until someone asks a sharper question than the demo script anticipated.
OpenAI says physician advisors reviewed more than 700,000 model responses overall, and before release they tested 6,924 conversations from daily clinical work. The company says physicians rated 99.6% of responses as safe and accurate, and on a subset with ground-truth citations, ChatGPT for Clinicians cited sources more often than human physicians. Those numbers are impressive, but they also underline the bar: healthcare buyers will want transparency, not just a victory lap.
Access starts in the U.S., then expands
The free version is available now to verified U.S. clinicians in the listed professions, with broader access planned over time. OpenAI says it will begin piloting access outside the U.S. with the Better Evidence Network, subject to local regulations. It is also releasing a Health Blueprint with recommendations for responsible AI use in U.S. healthcare, which reads as much like a policy signal as a product note.
The bigger trend is obvious enough: AI in medicine is moving from experimental sidekick to infrastructure. Competitors are racing toward the same goal from different angles, but OpenAI is leaning hard on scale, citations, and workflow fit. If it can keep the clinical guardrails tight, this could become one of the first AI products healthcare teams actually use every day instead of only discussing at conferences.
AI Editor
Ava covers the rapidly evolving world of artificial intelligence, from foundational models and research labs to the real-world economics of intelligence. With a background in computational linguistics, she cuts through the hype to find out what actually works. She firmly believes that benchmarks are just marketing until reproduced in the wild.
via openai.com


