Meituan has unveiled LongCat-2.0, a large language model with 1.6 trillion parameters and a context window of up to 1 million tokens, and the eye-catching part is not just the size. The company says the model was trained and run end-to-end on a cluster of 50,000 domestic ASIC accelerators, making it one of the clearest public examples yet of a frontier LLM built entirely on Chinese chips rather than Nvidia’s usual gravitational pull.
That matters because the AI race is no longer only about who has the most parameters or the flashiest benchmark score. It is also about who can assemble enough compute, networking, and software stack to train giant models without depending on foreign chips – a pressure that has pushed Chinese companies to squeeze more out of local silicon while Western labs keep leaning on familiar GPU supply chains.
A trillion-scale model built for agents
LongCat-2.0 is designed for agentic work: code writing, code editing, tool use, API calls, and multi-step reasoning. Meituan says the internal training corpus tops 30 trillion tokens and includes multilingual data plus programming code, which is exactly what you would expect from a model that wants to do more than politely autocomplete your sentence.
The model also uses LongCat Sparse Attention, or LSA, which trims the brutal cost of long-context processing by focusing on the most relevant tokens instead of comparing everything with everything. In practical terms, that is how Meituan claims the system can stretch to 1 million tokens without the usual quadratic pain that makes very long contexts so expensive.
Mixture of Experts keeps inference cheaper
LongCat-2.0 also uses a Mixture of Experts setup, with roughly 33-56 billion active weights per token rather than lighting up all 1.6 trillion parameters every time. That is the trick: keep the headline scale, but only pay for the parts of the model that matter for a given prompt.
Meituan pairs that with a Multi-Teacher On-Policy Distill scheme, or MOPD, where different specialist submodels teach one shared checkpoint. The company says the expert set covers agent behavior, reasoning for STEM and multi-step tasks, and instruction following with fewer hallucinations – a tidy division of labor, at least on paper.
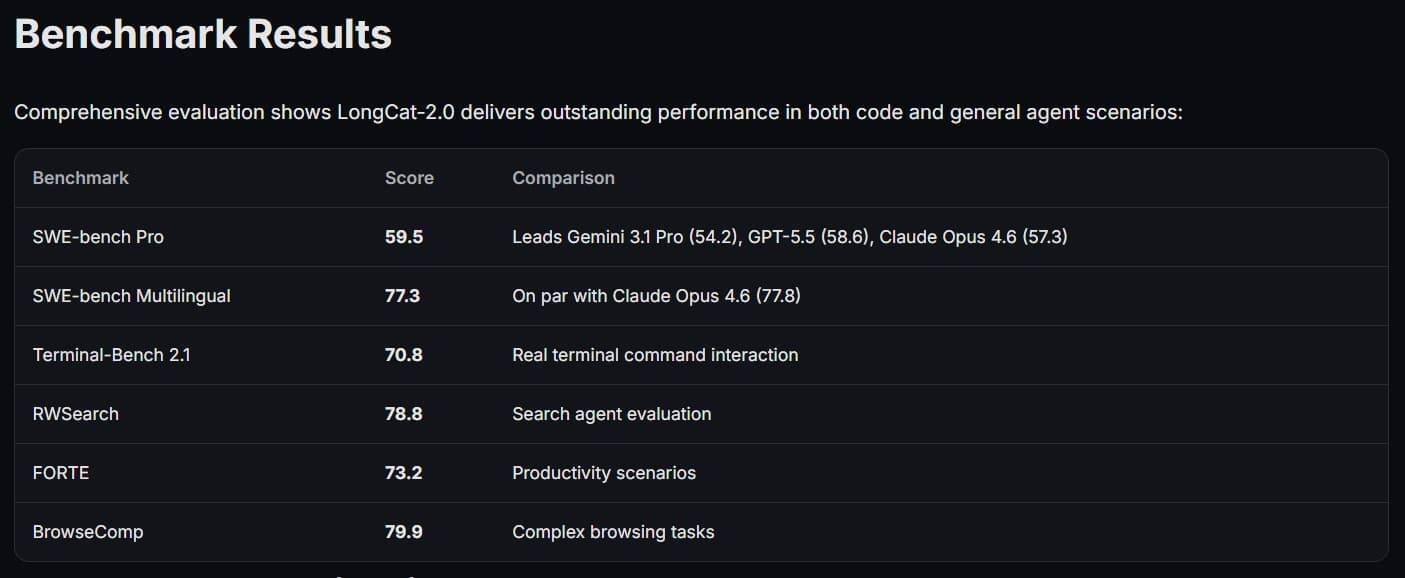
Benchmark wins, with the usual fine print
On SWE-bench Pro, Meituan says LongCat-2.0 scores 59.5 points, ahead of Gemini 3.1 Pro and close to GPT-5.5 and the latest Claude Opus models, while still trailing the strongest general-purpose leaders. It also posts strong results on Terminal-Bench 2.1 and on web-search and web-agent tasks, which fits the model’s stated focus much better than abstract leaderboard bragging rights.
- 1.6 trillion parameters
- Up to 1 million tokens of context
- 50,000 domestic ASIC accelerators used for full training and inference
- 30 trillion-plus token training corpus
- 59.5 on SWE-bench Pro
Meituan’s demos lean hard into practical automation: SQL agents, large-scale code refactors for new APIs, web apps generated from a single prompt, Three.js 3D scenes, and multi-agent text systems that try to stay coherent over long stretches of context. That is the real signal here. The next race in LLMs is looking less like a beauty contest for prose and more like a stress test for software that can actually do work.
The open question is whether this becomes a one-off showcase or a template others in China can copy at scale. If domestic chip stacks keep improving, Meituan’s release may be remembered less as a model launch than as a proof that frontier training on local hardware is no longer a theory.