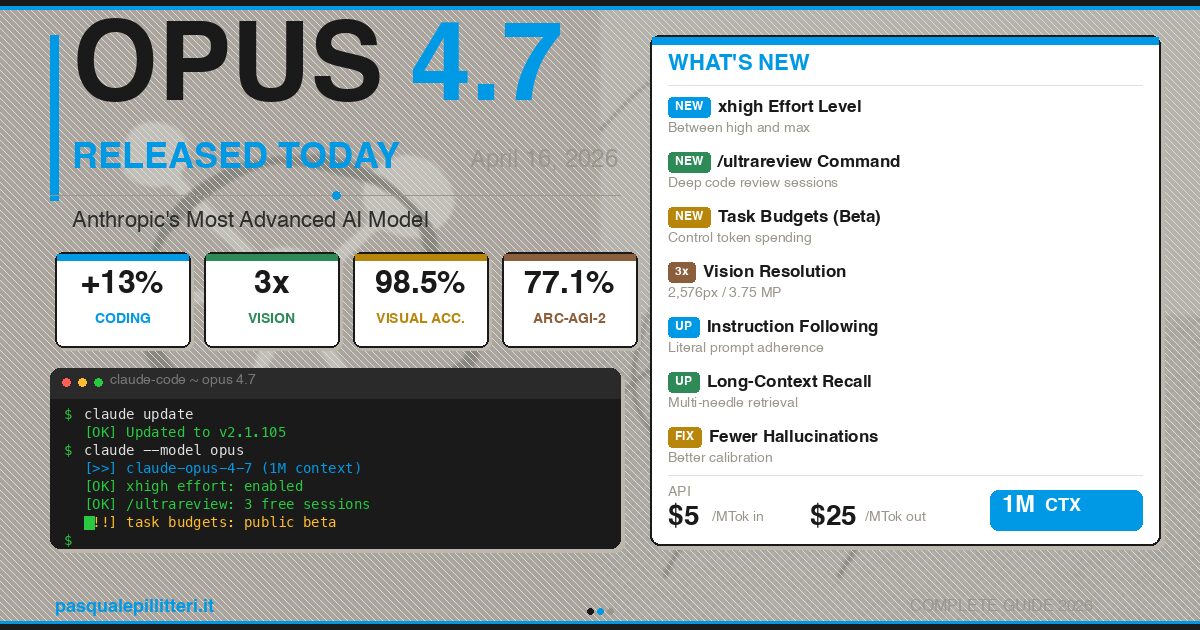
Anthropic has pushed Claude Opus 4.7 into the market with a very specific promise: better coding, sharper vision, and fewer surprises when the model is running long, messy tasks. The headline numbers are hard to ignore – +13% on coding benchmarks, 98.5% visual recognition in computer use, and a revamped long-context engine for the same 1 million token window.
The timing matters too. This lands only two months after Opus 4.6, which is fast by enterprise-model standards and a clear sign that Anthropic is trying to keep developers from drifting to rival stacks. OpenAI and Google may still grab attention with broader consumer splash, but Anthropic is sharpening its pitch around the people who actually pay for reliability: teams shipping code, automating workflows, and reading far too many PDFs.
Claude Opus 4.7 benchmark gains
The biggest jump is in coding. Anthropic says Claude Opus 4.7 scores +13% on a 93-task coding benchmark versus Opus 4.6, solves three times as many production issues on Rakuten-SWE-Bench, and reaches 70% on CursorBench, up from 58%. On ARC-AGI-2, it posts 77.1%, which places it ahead of Gemini 3 Pro on that style of abstract reasoning.
There is a catch, because there is always a catch: the model uses a new tokenizer that can consume roughly 1.0 to 1.35 times more tokens depending on content. That means better answers can come with a slightly uglier bill, which is exactly the sort of trade-off teams need to price into deployment instead of discovering after the fact.
- Input price: $5 per million tokens
- Output price: $25 per million tokens
- Context window: 1 million tokens
- Model ID: claude-opus-4-7
Claude Opus 4.7 vision upgrades
Vision is where Claude Opus 4.7 starts to look less like an incremental refresh and more like a practical tool upgrade. Anthropic says the model can now process images up to 2576 pixels on the long side, or about 3.75 megapixels, more than tripling the maximum supported by earlier Claude models.
That matters for technical diagrams, chemical structures, scanned documents, and UI screenshots, because blurry model vision is where a lot of automation dreams go to die. A jump from 54.5% to 98.5% visual recognition in computer use is not a polish update; it is the difference between ”occasionally useful” and ”actually trustworthy enough to automate a workflow.”
New Claude Code tools for heavy users
Anthropic is also adding features that make Opus 4.7 feel aimed at serious users rather than curious tinkerers. The new ”xhigh” effort level sits between ”high” and ”max”, giving developers a more usable middle ground when a task needs more thinking without the full cost and latency of max.
Claude Code also gets /ultrareview, a deeper code-review mode that checks architecture, security, performance, and maintainability instead of just nitpicking syntax. Pro and Max users get three free sessions, while Task Budgets in public beta let teams cap token spend during long refactors or migrations. That is the sort of feature enterprises ask for after the first expensive surprise, not before.
How to turn on Opus 4.7 in Claude Code
Updating is straightforward: refresh Claude Code, then select the model. Anthropic says users can run ”claude update”, install the latest package with npm, or pick the model directly with ”opus” or the specific model ID.
- Update the client: ”claude update”
- Select the model: ”/model opus” or ”claude –model claude-opus-4-7”
- Use the 1M-token mode: ”/model opus[1m]”
- Set it permanently in settings: ”model”: ”opus”
Claude Opus 4.7 is already available through Anthropic’s API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, Claude.ai and Claude Code. For Max, Team and Enterprise users, the 1M-token context is included in the plan; Pro users need to pay extra. If that sounds familiar, it should: the premium-model playbook has become ”pay for comfort, then pay again for scale.”
Instruction following in Claude Opus 4.7
The subtle change here is instruction following. Anthropic says Opus 4.7 is more literal than earlier versions, which is good news if your prompts are precise and bad news if they were written with a shrug. Short, vague prompts that used to work by accident may now fail more cleanly.
That is probably the most honest thing in the release. Better models do not rescue sloppy prompting forever; they just make the failure modes more obvious. The next few weeks should tell us whether developers treat Opus 4.7 as a smarter assistant, or simply as a stricter one.